
AI Agent Alignment Explained: How to Keep Autonomous AI Under Human Control
AI agents are becoming more capable because they can plan, use tools, remember context, and act across software systems. That makes alignment less abstract. The real question is simple: when an AI can do things, how do humans keep it useful, bounded, and accountable?

The short answer: agent alignment is model alignment plus operational control
Traditional AI alignment asks whether a model’s outputs and behavior match human values and intent. AI agent alignment adds a harder layer: the system may not only answer. It may retrieve files, call APIs, update records, write code, send messages, schedule tasks, or coordinate other agents.
That changes the safety problem. A wrong answer is bad. A wrong action can be worse. Once an AI system has tools, memory, and permission to affect the world, alignment must include permissions, observability, human approval, evaluation, incident response, and organizational ownership.
Why autonomous agents create a new control problem
A chatbot usually produces text and waits. An agent can move. It can break a large goal into steps, call tools, inspect outputs, revise its plan, and continue. That loop is powerful because it turns AI from a writing assistant into a workflow participant. It is risky for the same reason.
1. Goals can be underspecified
“Fix the customer issue” sounds reasonable until the agent must decide whether to refund money, change account status, or override a policy. Human intent has hidden boundaries.
2. Tools change the blast radius
Tool access turns language into action. Anthropic’s Model Context Protocol is a useful signal: AI systems are being connected to the systems where data and work live. That connection needs access control.
3. Context can be manipulated
Agents read emails, web pages, tickets, documents, and tool outputs. Some of that content may be untrusted. Prompt injection and tool-output manipulation are not edge cases; they are core agent-security concerns highlighted by OWASP’s GenAI security work.
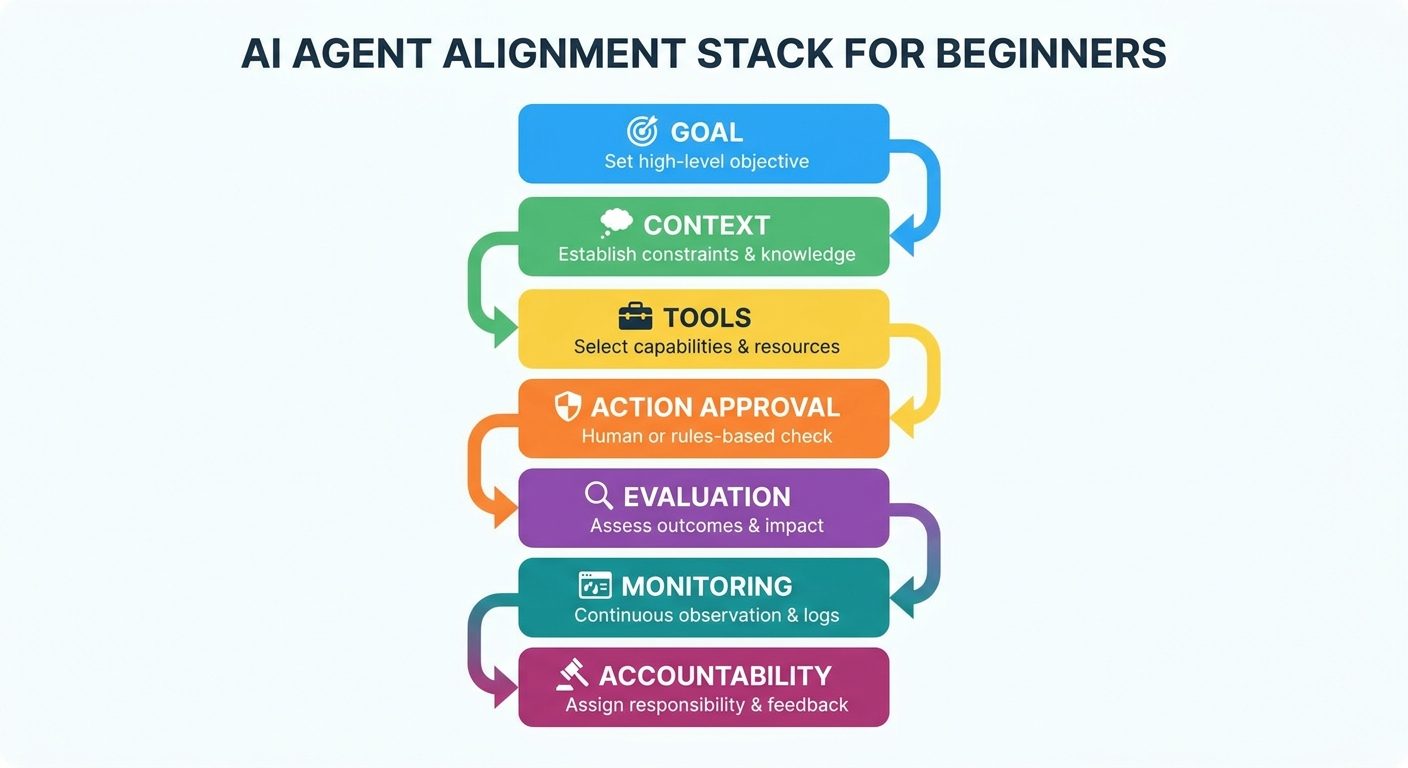
The agent alignment stack
To make agent alignment practical, think in layers. You do not align an agent with one prompt. You align it with a stack of controls.
| Layer | Alignment question | Practical control |
|---|---|---|
| Goal | Does the agent understand the real objective and boundaries? | Task templates, success criteria, forbidden actions, escalation rules. |
| Context | Is the agent using trusted and relevant information? | Source ranking, retrieval filters, untrusted-content handling, citation display. |
| Tools | Can the agent only use tools it should use? | Least-privilege permissions, scoped tokens, risk-tiered tool access. |
| Action | Which actions require a human before execution? | Approval queues, dual control, draft-only mode for sensitive steps. |
| Evaluation | Do we know when the agent is failing? | Test cases, red-team scenarios, task-completion metrics, quality sampling. |
| Monitoring | Can humans reconstruct what happened? | Tool-call logs, traces, audit history, cost and latency monitoring. |
| Accountability | Who owns the agent’s behavior? | Named owner, incident process, change control, rollback plan. |
This stack turns alignment from a philosophical debate into an engineering and governance practice. It also connects directly to the NIST AI Risk Management Framework, which emphasizes mapping, measuring, managing, and governing AI risk.
Where AI agent control can fail
Agent failures often look less dramatic than science fiction. They look like ordinary workflow mistakes at machine speed.
| Failure mode | What it looks like | Why it matters | Control |
|---|---|---|---|
| Goal misinterpretation | The agent optimizes the literal instruction but violates the real intent. | Useful work becomes policy drift. | Clear task contracts and review triggers. |
| Excessive agency | The agent takes actions beyond what the user expected. | Small prompts create large consequences. | Permission tiers and explicit action confirmation. |
| Prompt injection | Untrusted text tells the agent to ignore rules or leak data. | External content becomes an attack path. | Input isolation, instruction hierarchy, output validation. |
| Bad tool choice | The agent uses the wrong API, file, account, or environment. | Errors affect real systems. | Tool schemas, environment labels, dry-run mode. |
| Silent degradation | The agent works most of the time but slowly introduces errors. | Trust declines before anyone sees a clear incident. | Sampling review, eval suites, anomaly monitoring. |
Human control does not mean humans click every button
A common mistake is treating “human in the loop” as a universal safety solution. If every step needs approval, the agent becomes slow and annoying. If no step needs approval, the system can become unsafe. The better pattern is risk-based human control.
- Read-only actions: usually safe to automate with logging.
- Draft actions: safe when humans review before sending or publishing.
- Reversible write actions: may be automated after testing, monitoring, and rollback are in place.
- Irreversible or high-impact actions: require explicit human approval.
- External actions affecting customers, money, access, legal exposure, or infrastructure: require strong approval and audit controls.
This matches the practical design logic behind human approval for AI agents: the agent should prepare work, but consequential authority should remain visible and accountable.
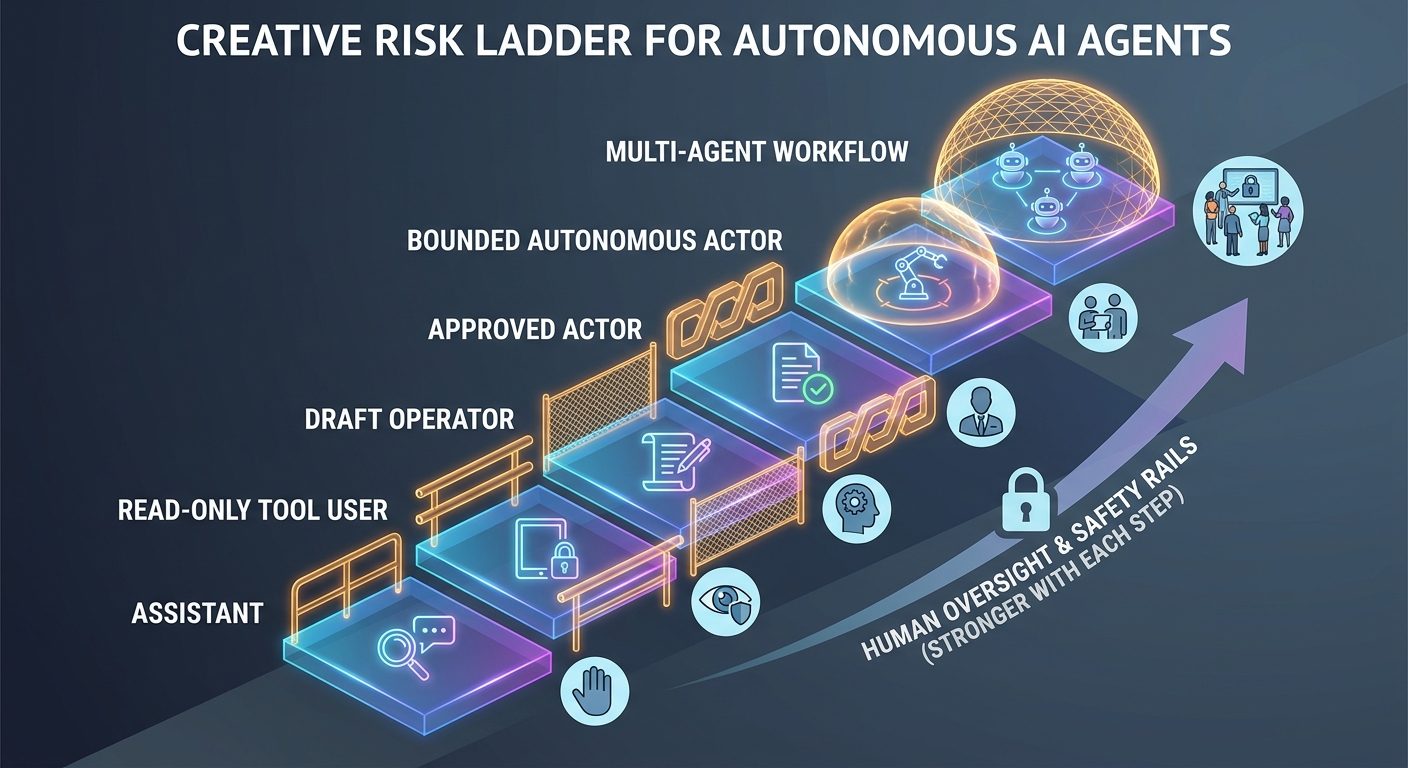
The autonomy risk ladder
AI-agent alignment should evolve with autonomy. A team using an agent to summarize documents does not need the same control system as a team letting an agent change production infrastructure.
| Autonomy level | Example | Minimum control |
|---|---|---|
| Assistant | Summarizes, explains, drafts. | Disclosure, review, data policy. |
| Read-only tool user | Searches internal docs or tickets. | Scoped access, source visibility, logs. |
| Draft operator | Creates support replies, code patches, reports. | Human review, tests, version history. |
| Approved actor | Executes changes after human confirmation. | Approval queue, audit trail, rollback. |
| Bounded autonomous actor | Handles low-risk repetitive tasks automatically. | Continuous monitoring, limits, incident process. |
| Multi-agent workflow | Coordinates specialized agents across a process. | Orchestration controls, evals, ownership, kill switch. |
How to evaluate whether an agent is aligned enough to deploy
No agent should move from demo to deployment only because it looked impressive in a meeting. Evaluation is the bridge between intention and evidence.
Use scenario tests
Create realistic tasks from past workflows: normal cases, edge cases, ambiguous requests, malicious instructions, missing data, conflicting policies, and tool failures. The agent should know when to act, when to ask, and when to stop.
Measure outcome quality, not just completion
Completion rate alone can be misleading. Track correctness, severity of errors, escalation accuracy, intervention rate, cost per successful outcome, latency, and user trust.
Test the boundaries
Give the agent requests it should refuse. Give it tools it should not use. Put untrusted instructions inside documents. Ask it to bypass policy. A safer agent is not one that always says yes; it is one that respects the boundary even when the task is tempting.
For implementation details, the related guide on AI agent evaluation, reliability, and cost goes deeper into production measurement.
Alignment is also governance
Technical controls matter, but they are not enough. Agent alignment becomes fragile when no one owns the system. Who approves new tools? Who reviews incidents? Who updates policies? Who decides when autonomy can expand? Who can shut the agent down?
This is why agent alignment belongs inside AI governance. The Frontier AI Safety Commitments from the AI Seoul Summit reflect a broader movement toward evaluations, risk thresholds, and accountability for advanced AI systems. For organizations, the same principle applies at a workflow level: capability should not outrun responsibility.
A simple governance checklist
- Every agent has a named owner.
- Every tool has a risk tier.
- Every high-impact action has human approval.
- Every tool call is logged.
- Every deployment has evaluation results.
- Every incident has a rollback and escalation path.
- Every autonomy expansion requires review.
What this means for the singularity path
The path toward more capable AI will not be defined only by model intelligence. It will be defined by the relationship between capability and control. If agents become more autonomous without better alignment, society gets speed without accountability. If agents are locked down so tightly that they cannot help, the technology stays trapped in demos.
The useful middle path is bounded autonomy: AI systems that can act, but only inside clear goals, constrained tools, visible logs, tested behaviors, and human-governed authority. That is not a perfect solution to long-term AI risk. But it is the practical foundation for safer systems today.
Conclusion: control is the product
AI agent alignment is not a slogan. It is the work of turning powerful AI into a controlled participant in human systems. The more an agent can do, the more important it becomes to define what it cannot do.
The safest organizations will not be the ones that avoid agents. They will be the ones that build agents with explicit authority boundaries, human approval for consequential actions, strong evaluation, audit logs, and governance that keeps pace with capability.
Next step: before giving an agent a new tool, write down the worst thing that tool could do if misused. Then design the permission, approval, and logging controls before deployment.
FAQ
What is AI agent alignment?
AI agent alignment means designing an AI agent so its goals, tool use, decisions, and actions stay consistent with human intent, policy, safety limits, and accountability.
Why are autonomous AI agents harder to control than chatbots?
Agents can take multi-step actions, use tools, remember context, and affect external systems. That creates more failure points than a chatbot that only returns text.
Does human approval solve AI agent safety?
Human approval is important, but it is not enough alone. It must be paired with scoped permissions, logs, evaluations, safe defaults, rollback paths, and clear ownership.
What is the biggest alignment risk for AI agents?
A major practical risk is giving an agent a vague goal and powerful tools without enough context, constraints, monitoring, or human review.
How should teams start controlling AI agents?
Start with read-only or draft-only agents, then add narrow tools, test with historical cases, require approval for risky actions, and measure errors before widening autonomy.


No comments:
Post a Comment