
Durable AI Agent Workflows: Retries, Human Approval, and Production Reliability
Durable AI agent workflows are the difference between an impressive demo and a system that can survive real work. A demo agent can read a prompt, call a tool, and produce a good answer while everything is clean. A production agent has to keep going when an API times out, a model returns an uncertain result, a worker crashes, a webhook arrives late, or a human reviewer takes two days to approve the next step.
The practical goal is simple: every important agent task should have a memory of what already happened, a policy for what to retry, a boundary for what needs human approval, and an audit trail that explains why the final action was taken. Without those pieces, the agent may look autonomous, but the system is still fragile background-job code with a model call in the middle.
This guide is for builders who already understand the basics of agents and now need to make them reliable. If you are still mapping the full architecture, start with How to Build AI Agents in 2026, then use this article as the production workflow layer that sits around planning, tools, memory, and evaluation.
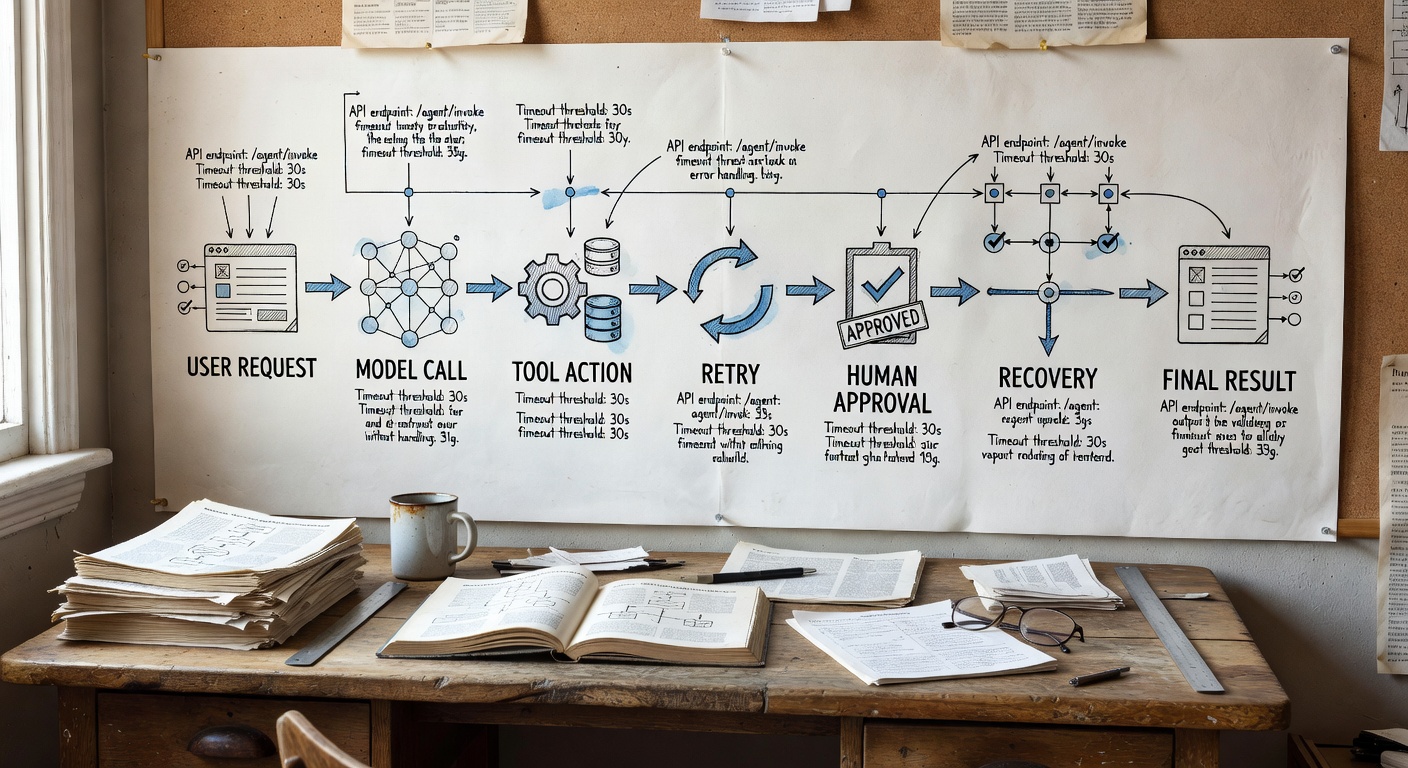
What Makes an Agent Workflow Durable?
A durable workflow preserves progress across interruptions. It does not assume that a single process, chat session, or request handler will remain alive until the work is finished. Instead, it records each meaningful step, separates orchestration from side effects, and resumes from known state when something fails.
That matters because agent work is often multi-step. A support agent may classify a case, search internal docs, draft a refund decision, wait for approval, update a CRM, and notify a customer. A coding agent may inspect an issue, read files, propose a patch, run tests, ask for clarification, and create a pull request. A research agent may gather sources, score confidence, generate a memo, and schedule a follow-up check. Each step can fail independently.
Modern workflow platforms are starting to package this durability directly for AI use cases. Mistral describes Mistral Workflows as a way to build multi-step AI processes that combine LLM calls, tool use, external APIs, and human input while surviving crashes, restarts, and individual step failures. Its durable-agent documentation also frames agent loops as workflows where model calls, tools, handoffs, and session state can survive restarts through Durable Agents.
You do not need one specific vendor to apply the pattern. The agent is not the workflow. It is a reasoning component inside a workflow. The workflow owns persistence, retries, approvals, deadlines, observability, and recovery.
The Production Failure Modes Demos Hide
Agent reliability problems usually appear after the first successful demo because the demo path is too clean. The model answers, the tool works, and the user approves the result quickly. Production adds messier timing, partial failure, and unclear ownership.
1. The Same Step Runs Twice
Retries are useful only when the operation is safe to retry. If an agent sends an email, charges a card, posts a comment, or modifies a file, repeating the action can create damage. Durable workflows need idempotency keys and step records so the system can say, “this action already succeeded,” instead of performing it again after a crash.
2. The Agent Forgets Why It Chose a Tool
Short-term chat context is not enough for production. If an agent calls a tool, the workflow should record the input, the output, the policy that allowed the call, and the next decision. This is separate from long-term semantic memory. It is operational memory: a trace of the run.
3. Human Review Becomes an Afterthought
Many teams say “we will keep a human in the loop,” then build a system where the only human option is to approve a final blob of text. Useful review needs a structured checkpoint: what action is requested, what evidence supports it, what risks remain, what happens if the reviewer rejects it, and when the workflow expires.
4. Tool Errors Are Treated Like Model Errors
A model uncertainty problem and a payment API timeout are different failures. One may require a different prompt, a cheaper classification model, or an abstention. The other may require exponential backoff, a circuit breaker, or a manual operations task. Durable workflows should classify failures before deciding whether to retry.
5. Nobody Can Explain the Final Action
If a customer asks why an account was suspended, or an engineering lead asks why an agent edited a file, “the model decided” is not an acceptable answer. A durable workflow should produce a run record: inputs, important intermediate decisions, tool calls, approvals, policy checks, and final outcome.
A Practical Architecture for Durable AI Agent Workflows
Most reliable agent workflows have six layers. They can be implemented with a workflow engine, a queue plus database, or a managed agent runtime, but the responsibilities should remain explicit.
1. Workflow State
Workflow state is the source of truth for the run. It should include the run ID, user or system owner, current step, completed steps, pending approvals, attempt counts, deadlines, and references to artifacts. Keep large documents and outputs in object storage or a document system; keep the workflow record small and structured.
2. Agent Step
The agent step is where the model reasons over the task. It may plan, choose tools, draft output, or decide whether it has enough evidence. The agent should not directly own irreversible side effects. It should propose actions into the workflow, where policy and execution layers can inspect them.
3. Tool Execution Layer
Tool calls are where the outside world changes. Search, database reads, code execution, CRM updates, tickets, emails, and file writes should be wrapped as explicit activities with inputs, outputs, timeouts, permission checks, and retry policies. For deeper tool design, see AI Agent Tools Explained.
4. Reliability Policy
The reliability policy decides what gets retried, what gets skipped, what gets escalated, and what stops the run. It should be written before launch, not improvised after the first incident. A good policy distinguishes transient infrastructure failures, validation failures, policy failures, low-confidence model outputs, missing user input, and irreversible side-effect failures.
5. Approval and Escalation Layer
Approval is a product surface, not just a boolean flag. Reviewers need enough context to make a fast decision. The approval layer should show the proposed action, evidence, risk class, cost impact, policy checks, and rollback path. It should also support rejection reasons so the workflow can continue intelligently instead of simply failing.
6. Observability and Evaluation
Every serious agent workflow needs traces, metrics, and evaluation cases. OpenAI’s Agents SDK documentation describes tracing as a way to capture model generations, tool calls, handoffs, guardrails, and custom events during an agent run. That kind of trace is not just for debugging; it becomes training data for better prompts, better tools, and better approval rules. The related Agents SDK tracing guide is a useful reference for what a run record can include.
The Durable Workflow Scorecard
Before you ship an agent workflow, score it across eight questions. A weak answer does not always mean you should stop; it means the system is still a pilot, not a production workflow.
1. What Is the Unit of Work?
Define the workflow in business terms. “Run the agent” is too vague. Better units are “triage one support ticket,” “draft one vendor-risk review,” “prepare one pull request,” or “update one customer record after approval.” A clear unit of work makes retries, cost, ownership, and success metrics easier to define.
2. Which Steps Are Deterministic?
Separate predictable orchestration from probabilistic model behavior. Routing to the next step, enforcing a timeout, checking whether approval exists, and marking a run as complete should be deterministic. Drafting a summary or choosing evidence may involve the model. Mixing those responsibilities makes recovery harder.
3. Which Actions Are Safe to Retry?
Classify every tool call. Pure reads are usually safe. Draft generation is usually safe if stored under a new artifact version. External writes need idempotency keys. Irreversible actions, such as sending money or notifying a customer, should usually require a final approval gate and a record that prevents duplicate execution.
For the detailed implementation pattern, use AI agent idempotency to give each risky external action a stable operation identity across retries and approval resumes.
4. Where Does Human Approval Happen?
Do not wait until the final output if the risky action happens earlier. A code agent may need approval before applying a patch to a protected branch. A finance agent may need approval before posting an invoice adjustment. A support agent may need approval before sending a legal-sensitive response. Approval belongs before the side effect.
5. What Does the System Do With Low Confidence?
Low confidence should have a route. The agent can gather more evidence, ask the user a specific question, hand off to a human, use a stronger model, or stop with a clear reason. Treating low confidence as a normal answer path silently transfers risk to the user.
6. What Is the Cost Budget?
Durability can accidentally increase cost because retries, rechecks, and long-running workflows keep consuming model and tool resources. Set budgets per run: maximum model calls, maximum tool calls, maximum execution time, and maximum retry attempts. When a run exceeds the budget, escalate instead of looping.
7. What Trace Would You Need During an Incident?
Assume a customer, auditor, or manager will ask what happened. You need the run ID, user intent, model steps, tool calls, policy checks, approval decisions, failures, retries, final action, and artifacts. If your trace cannot answer those questions, your incident review will become guesswork.
8. How Will You Know the Workflow Improved?
Durable workflows should be evaluated over time. Track task success rate, human override rate, retry rate, average cost per completed task, time to approval, escalation rate, and incident count. Evaluation should use real completed runs, not only synthetic prompts.
Example: A Durable Support Refund Agent
Consider a support agent that helps process refund requests. A fragile version reads the customer message, asks a model for a decision, and sends the answer. A durable version turns the work into a controlled sequence.
First, the workflow creates a refund-review run with a unique ID. It records the customer, order ID, policy version, and request source. Next, the agent summarizes the request and proposes what evidence it needs. Tool activities fetch order status, payment history, prior support tickets, and policy rules. Each tool call has a timeout and a retry policy. If the order API fails twice, the workflow pauses and creates an operations task instead of letting the model guess.
After evidence collection, the agent drafts a recommendation: approve, reject, request more information, or escalate. The workflow validates that the recommendation includes evidence references and a policy citation. For low-value refunds under clear rules, the system may allow automatic approval. For high-value, suspicious, or legally sensitive cases, it creates a human approval task.
The reviewer sees a compact approval screen: customer request, evidence summary, policy match, proposed message, refund amount, risk flags, and rollback path. If approved, the workflow calls the refund API with an idempotency key. If the API returns a transient error, the workflow retries. If it succeeds, the workflow records the transaction ID and sends the customer message. If the reviewer rejects the recommendation, the workflow returns to the agent with the rejection reason and asks for a revised draft or escalation note.
This is still an AI agent workflow, but the reliability comes from the system around the agent. The model helps interpret and draft. The workflow controls progress, records state, and protects side effects.
Retries: The Rules That Prevent Expensive Chaos
Retries sound simple until they meet side effects. The safest starting point is to assign each activity one of four retry classes.
Read Activities
Searches, database reads, document retrieval, and status checks can usually be retried with backoff. Still log attempts and timeouts, because repeated read failures may point to permission or dependency problems.
Draft Activities
Model calls that create drafts can be retried if each output is versioned. Keep the prompt, model identifier, input references, and output artifact ID. Do not overwrite the only copy of a draft without preserving the history.
Write Activities
External writes need idempotency. Use keys, natural unique constraints, or “check before write” records so a retry does not create duplicate tickets, duplicate messages, duplicate payments, or duplicate file edits.
Irreversible Activities
Some actions should not be retried automatically after an ambiguous failure. If the agent cannot confirm whether the external system completed the action, pause and escalate. A human or reconciliation job should resolve the uncertainty.
Human Approval Should Be Designed, Not Bolted On
Approval gates work when the reviewer can quickly understand the decision. A useful approval object includes the proposed action, evidence links, confidence, risk tier, policy checks, expected cost, deadline, and reject options. “Looks good?” is not enough.
Approval gates also need ownership. Who can approve? What happens on weekends? Does a missing approval expire the run, escalate it, or send a reminder? Can a reviewer edit the output, or only approve and reject? These are workflow questions, not model questions.
Guardrails can help decide whether a workflow is allowed to proceed. OpenAI’s Agents SDK guardrails guide distinguishes input, output, and tool guardrails, including checks around tool invocations. In a durable workflow, guardrails should write structured results into the run record so that a reviewer can see which checks passed, failed, or triggered escalation.
What to Log Without Creating a Privacy Problem
Durable workflows need enough history to recover and explain decisions, but logging everything creates privacy and security risk. Store references when possible. Redact secrets before trace export. Separate operational metadata from sensitive content. Give each workflow a retention policy.
A practical run record should include the run ID, task owner, workflow version, policy version, current step, status, timestamps, tool names, attempt counts, approval decisions, artifact references, and final outcome. Sensitive documents, customer messages, credentials, and model outputs should follow your normal data retention and access-control rules.
A Launch Checklist for Durable AI Agent Workflows
Use this checklist before turning a pilot into a production feature.
- Define one clear unit of work and one accountable owner.
- Store workflow state outside the model context window.
- Separate orchestration logic from model reasoning and side effects.
- Wrap every tool call as a typed activity with timeout, retry, and permission rules.
- Use idempotency keys for external writes.
- Put approval gates before risky or irreversible actions.
- Record guardrail results, reviewer decisions, and policy versions.
- Set per-run budgets for model calls, tool calls, retries, and elapsed time.
- Trace enough run history to debug incidents without over-logging sensitive data.
- Measure task success, human override rate, retry rate, cost, and incident count.
FAQ
Do all AI agents need durable workflows?
No. If an agent answers a low-risk question in a single request and does not call sensitive tools, a normal request-response architecture may be enough. Durability becomes important when work is multi-step, long-running, expensive, approval-based, or connected to external side effects.
Is durable execution the same as agent memory?
No. Agent memory usually refers to context the agent can use for reasoning, such as user preferences, prior conversations, or retrieved documents. Durable workflow state is operational memory: what step the system is on, what already ran, what failed, what was approved, and what should happen next. For the reasoning side, read AI Agent Memory Explained.
Can I build durable workflows with just a database and queue?
Yes, especially for simple cases. A database can store state, a queue can schedule work, and workers can process steps. The tradeoff is that you must build retries, timeouts, replay behavior, observability, versioning, and human approval handling yourself. Workflow engines and managed platforms exist because those details become complex quickly.
What is the most common mistake?
The most common mistake is letting the model directly trigger side effects without a workflow boundary. The agent should propose or request actions. The workflow should enforce policy, approval, idempotency, and logging before executing them.
How should teams start?
Pick one repeatable workflow with clear business value and limited blast radius. Add state, tracing, retry classes, and one approval gate. Launch it to a small internal group. Use the run records to improve prompts, tools, policies, and evaluation cases before expanding scope.
Conclusion
Durable AI agent workflows turn agents from clever sessions into accountable systems. The core shift is to stop treating the model as the whole application. The model can plan, draft, classify, and choose tools, but the workflow must own state, retries, approvals, budgets, observability, and recovery.
That architecture is less glamorous than a demo, but it is what makes agents useful in real operations. If an agent workflow can pause for a reviewer, resume after a crash, avoid duplicate side effects, explain its decisions, and improve from measured outcomes, it is on the path from experiment to production.


No comments:
Post a Comment