
AI Agent Idempotency: How to Prevent Duplicate Tool Actions
AI agent idempotency is the discipline of making sure an agent can retry, recover, or replay a step without accidentally performing the same real-world action twice. It matters whenever an agent can send email, create invoices, update tickets, approve refunds, trigger deployments, write to a database, or call another system that changes state.
This article is a practical cluster under Durable AI Agent Workflows. That pillar explains why production agents need retries, human approval, and recovery. Idempotency is the narrower engineering pattern that keeps those retries from becoming duplicate payments, duplicate messages, duplicate support actions, or duplicate data writes.
What Idempotency Means for AI Agents
In software, an idempotent operation can be repeated and still produce the same final effect. For an AI agent, the harder problem is not the model's text. It is the agent's side effects. A model may reason through the same plan twice after a timeout, a worker restart, a browser refresh, a webhook retry, or a human approval delay. If the action is read-only, repetition is usually harmless. If the action changes another system, repetition can be expensive.
Imagine a billing assistant that decides to refund a customer. The first tool call reaches the payment provider, but the agent runner times out before it receives the response. Without idempotency, the retry may issue another refund. With idempotency, both attempts carry the same operation identity, and the system treats the retry as the same intended refund.
The key idea is simple: every risky tool action needs a stable identity that survives retries. The implementation details are where most teams make mistakes.
Where Duplicate Tool Actions Come From
1. Network Timeouts
The agent calls an external API, the API succeeds, but the response is lost. From the runner's point of view, the call failed. From the external system's point of view, the action already happened. Retrying blindly is the classic duplicate-action bug.
2. Worker Restarts and Queue Redelivery
Long-running agents often run through queues, workflow engines, or background jobs. If a worker crashes after sending an action but before marking the step complete, the same job may be delivered again. Durable execution platforms reduce this risk, but they do not remove the need for idempotent activities. Temporal's documentation on retry policies is useful background because retries are expected behavior, not an edge case.
3. Human Approval Delays
Approval flows create a pause between the agent's proposed action and the final execution. During that pause, the request may be refreshed, reassigned, edited, or resumed in a different process. If the approval record and the tool action do not share a stable operation ID, the final execution can happen more than once.
4. Webhook Retries
Many systems retry webhooks until they receive a successful response. An AI agent that reacts to webhooks must deduplicate both the incoming event and any outgoing action caused by that event. Otherwise a single ticket update, payment event, or deployment notification can trigger repeated tool calls.
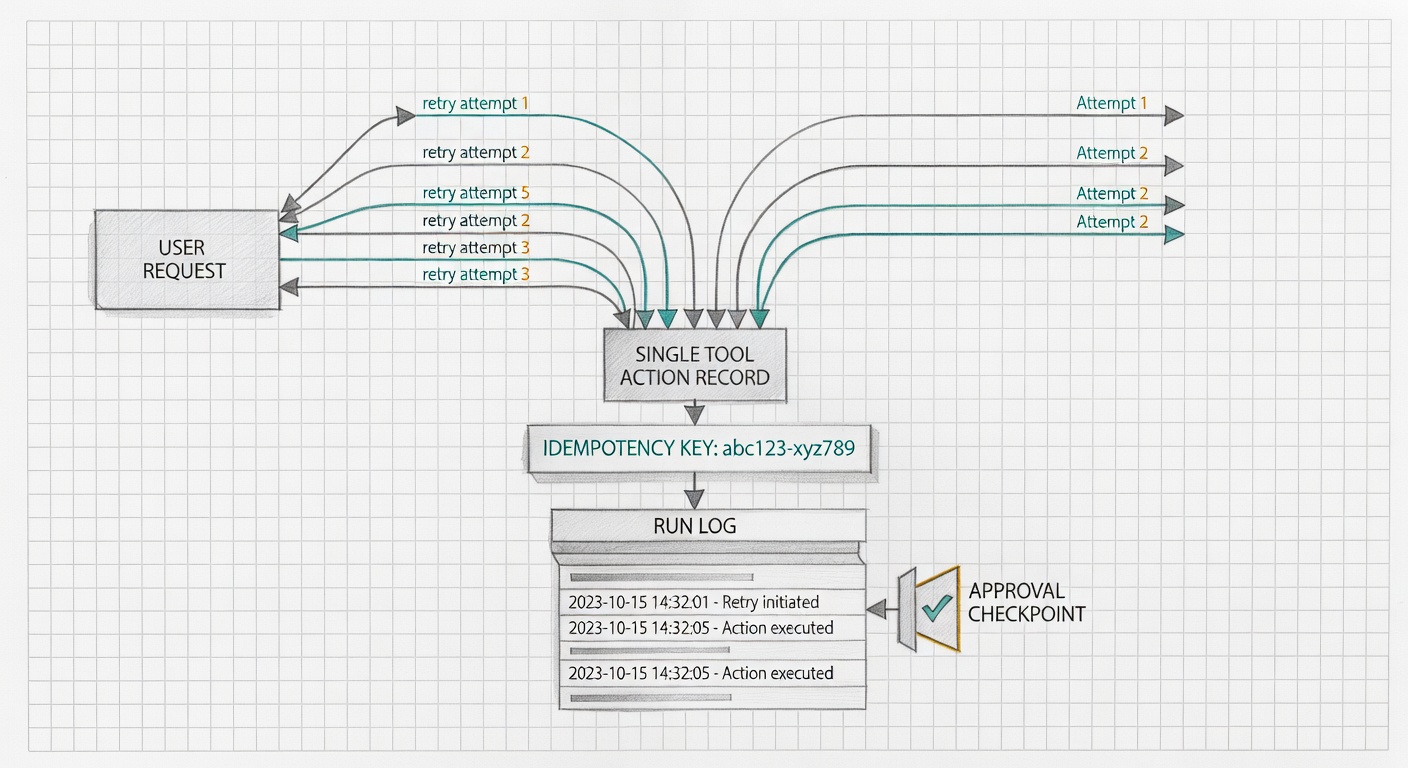
The Idempotency Key: Small Field, Big Contract
An idempotency key is a unique value that says, "these attempts represent the same intended operation." The key is sent with a mutating request or stored beside a tool call before execution. If the system sees the same key again, it should return the first outcome or reject the duplicate according to a clear rule.
Stripe's idempotent request documentation is a useful reference because it shows the pattern in a high-stakes API: a client supplies a key for a POST request, and repeat attempts with the same key do not create a new independent operation. AWS also explains the broader distributed-systems reasoning in Making retries safe with idempotent APIs.
For AI agents, the idempotency key should usually be generated by your application, not improvised by the model. A model can suggest an action, but the runtime should assign the stable operation identity because the runtime sees the user request, workflow run, tool name, approval state, and previous attempts.
Design the Key Before You Design the Retry
A weak idempotency key is almost as dangerous as no key. If the key changes on each retry, it cannot deduplicate anything. If the key is too broad, it may collapse separate legitimate actions into one outcome. The right key identifies one intended business action.
A Practical Key Formula
For many agent tools, a good starting formula looks like this:
idempotency_key = hash(
tenant_id,
user_request_id,
workflow_run_id,
tool_name,
target_resource_id,
normalized_action_payload
)The exact fields depend on the domain. A refund action may include tenant ID, order ID, amount, currency, and reason code. A deployment action may include repo, environment, commit SHA, and release plan ID.
The important property is stability. If the agent retries the same planned action, the key must stay the same. If the user asks for a genuinely new action, the key must change.
Do Not Put Raw Model Text in the Key
Model text is noisy. The same action may be described as "refund the customer" on one attempt and "issue a refund" on another. If raw natural language becomes part of the key, equivalent retries can look different. Normalize the action into structured fields first, then hash those fields. The model can fill a schema, but your application should canonicalize and validate it before committing the key.
Build an Idempotency Store
The key needs a place to live. An idempotency store tracks the operation key, normalized request payload, status, outcome, timestamps, and the external reference returned by the tool. It should be written before the side effect happens, using a uniqueness constraint on the key.
A simple table can carry a production system a long way:
- operation_key: unique idempotency key for the intended action.
- tool_name: the mutating tool being called.
- payload_hash: hash of the normalized action payload.
- status: pending, running, succeeded, failed_retryable, failed_final, or needs_review.
- external_reference: payment ID, ticket comment ID, deployment ID, email message ID, or similar.
- first_seen_at and last_attempted_at: timestamps for debugging and cleanup.
- workflow_run_id and trace_id: links back to the agent run log.
The first worker to insert the key owns the execution. A second worker seeing the same key should load the existing record and follow the stored status. If the original outcome is known, return it. If the operation is still running, wait, return a conflict, or move the request into reconciliation.
Make Tool Calls Retry-Safe
Separate Planning from Acting
A reliable agent does not jump straight from model output to an external write. It plans the action, validates the action, records the operation key, then executes the tool. This separation gives you a place to deduplicate before any side effect occurs.
Tool calling systems make it easy for a model to request structured actions; OpenAI's function calling guide is one example. But structured arguments are not enough. The runtime still needs policy checks, operation identity, approval state, and storage.
Classify Tools by Side Effect
Do not give every tool the same retry behavior. Read tools can usually retry freely. Draft tools can retry if they only create internal proposals. Stage tools need stable operation IDs. Execute tools need the strongest idempotency, approval, and reconciliation logic.
If you are still defining the tool taxonomy, start with agent tool design and approval boundaries, then add idempotency to the execute-level tools.
A useful classification looks like this:
- Read: search, fetch, retrieve, inspect, summarize. Low risk.
- Draft: create a suggested email, refund note, ticket reply, or SQL change without sending it. Medium-low risk.
- Stage: create a queued action that still needs confirmation. Medium risk.
- Execute: send, refund, deploy, update, delete, grant access, or call a third-party write API. High risk.
Only execute tools should be able to change the outside world, and every execute tool should require an idempotency key.
Practical Example: Refund Agent
Consider an agent that helps a support team issue refunds. The user asks, "Refund order 4817 because the replacement item never arrived." The model decides a refund is appropriate and calls issue_refund.
A weak implementation passes the model arguments straight to the payment API. If the payment API succeeds but the agent runner times out, the retry may issue another refund.
A stronger implementation follows this sequence:
- Validate that the order exists and belongs to the tenant.
- Normalize the action payload: order ID, amount, currency, reason code, and customer account.
- Create an idempotency key from the tenant, workflow run, tool name, order ID, amount, currency, and normalized reason.
- Insert the key into the idempotency store with status
pending. - If policy requires approval, attach the same key to the approval record.
- Call the payment provider with the same key or store the provider request ID beside it.
- Update the idempotency record with the provider's refund ID and final status.
- If a retry sees the same key, return the stored refund ID instead of creating a new refund.
This pattern also gives support, finance, and engineering a shared audit trail. The conversation, approval, tool call, webhook, and final ticket note all point to the same operation.
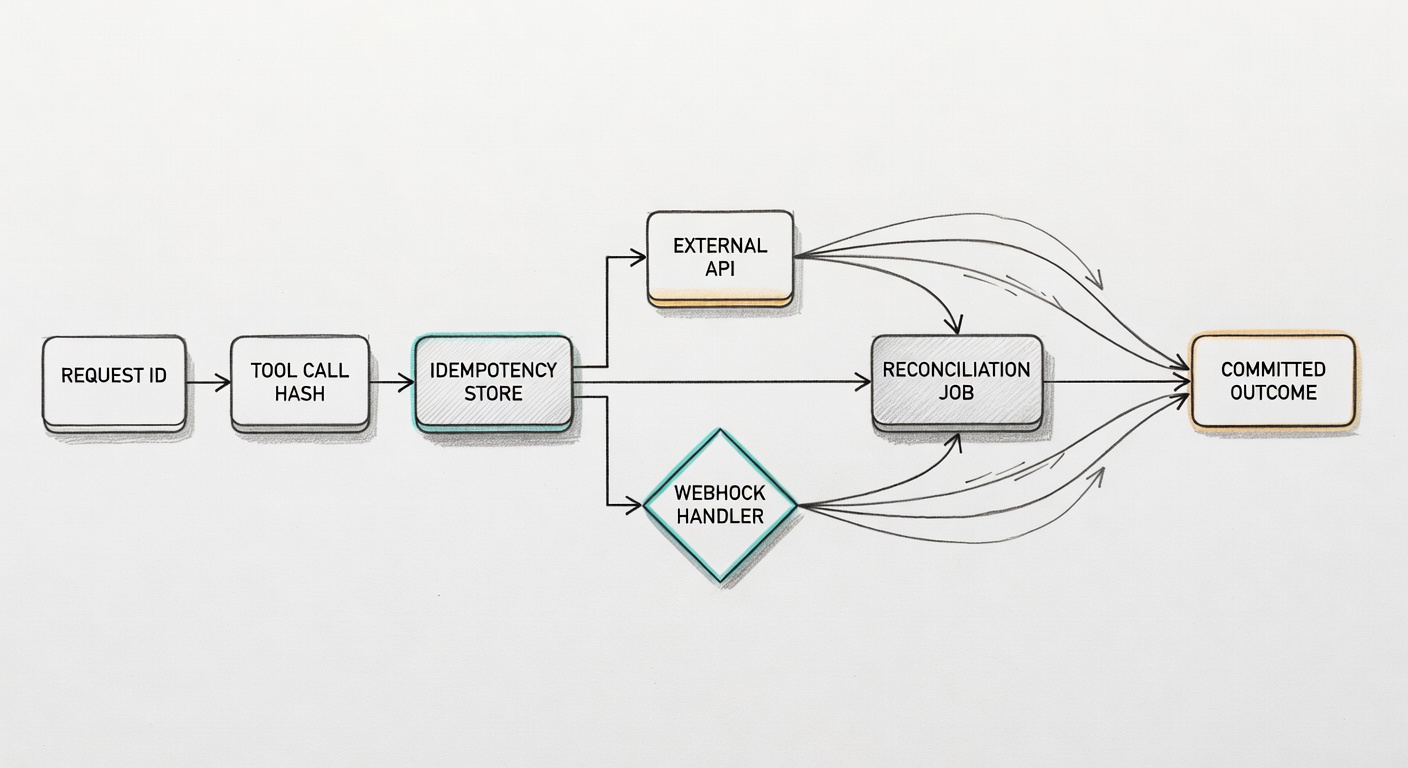
Handle Webhooks and Reconciliation
Idempotency does not stop at the outgoing tool call. External systems may send webhooks more than once, deliver them out of order, or deliver a success event after your runner has already marked an attempt as failed. Treat incoming webhooks as another deduplication problem.
Store webhook event IDs and ignore duplicates. Link each webhook to the operation key when possible. If the external system reports success but your record is still pending, reconcile the record rather than retrying. A scheduled job should query the external system before trying again.
This is especially important for payment, provisioning, access-control, and deployment tools. In those domains, "try again" should be the last step after checking whether the first attempt already changed the world.
Approval Queues Need Idempotency Too
Human approval is not a substitute for idempotency. An approval queue should show the intended action, normalized payload, operation key, risk tier, and expected external effect. When a reviewer approves the action, execution should use the same key created when the action was staged.
If a reviewer clicks approve twice, refreshes the page, or approves while a worker is recovering, the system should still execute once. The button should be disabled quickly in the interface, but the backend must enforce the rule. Interface protection is helpful; durable operation identity is the real control.
Common Mistakes
- Using a new key for each attempt: a UUID generated inside the retry loop is just a request ID. Generate the key before the first attempt and reuse it.
- Deduplicating only by user message: two identical messages may represent two real actions. Include target resources and normalized action fields.
- Ignoring payload mismatches: if the same key appears with a different payload hash, route to review or mark the operation conflicted.
- Assuming the external API handles everything: provider idempotency helps one call, but your workflow still needs its own operation record.
A Launch Checklist for AI Agent Idempotency
- List every tool that can change external state.
- Require an idempotency key for each execute-level tool.
- Generate keys in application code, not free-form model text.
- Normalize action payloads before hashing or storing them.
- Create a unique operation record before calling external systems.
- Store payload hashes and reject mismatched retries.
- Link approvals, webhooks, traces, and external references to the same operation key.
- Add reconciliation for stuck operations before automatic retry.
- Test worker crash, timeout, double-click approval, duplicate webhook, and out-of-order webhook cases.
- Expose operation status in support and incident review tools.
FAQ
Is idempotency only needed for payments?
No. Payments are the obvious case because duplicate charges and refunds are painful, but the same pattern applies to emails, ticket comments, CRM updates, database writes, access grants, deployments, data exports, and workflow approvals.
Should the model create the idempotency key?
Usually no. The model can propose the action, but application code should create the key from stable structured fields. This avoids key drift caused by wording changes and keeps the idempotency contract under your control.
How long should idempotency records live?
It depends on the business risk and retry window. A low-risk notification might need a short retention period. A payment, access-control action, or deployment may need a much longer audit trail. Choose retention based on how long duplicates would still matter and how long external systems may send delayed events.
Does a workflow engine make idempotency unnecessary?
No. A workflow engine can make retries and recovery more predictable, but any activity that changes the outside world still needs idempotent behavior. The workflow can remember that it called a step; the external system may still have received a request whose response was lost.
Conclusion
AI agent idempotency is not a decorative reliability feature. It is the difference between an agent that can recover safely and an agent that turns uncertainty into duplicate side effects. The pattern is straightforward: classify risky tools, generate stable operation keys, store them before execution, reuse them across retries, deduplicate incoming webhooks, and reconcile unknown outcomes before acting again.
As agents move from demos into production workflows, the safest systems will not be the ones that never fail. They will be the ones that can fail, retry, resume, and still perform each intended action once.


No comments:
Post a Comment