
Frontier AI Safety Case: What Evidence Teams Need Before Deployment
A frontier AI safety case is a structured, evidence-backed argument that an AI system is safe enough for a specific deployment context. It does not promise perfect safety. It forces teams to state what must be true, what evidence supports the claim, where the claim applies, and when deployment should stop.

Frontier AI safety case: the quick answer
A frontier AI safety case is a structured argument, supported by evidence, that an AI system is safe enough for a defined operational context. That wording matters. It is not a vibe, a policy slogan, or a single model evaluation score. It is an argument with a boundary: this system, with these capabilities, used by these people, under these constraints, with this monitoring, is acceptable for this specific deployment decision.
The idea comes from safety-critical industries and is now being adapted to frontier AI governance. GovAI’s research on safety cases for frontier AI describes safety cases as reports that make a structured argument, supported by evidence, that a system is safe enough in a given operational context. The UK AI Security Institute frames them as a complement to empirical model evaluations, especially for future systems where autonomy, loss of control, or deployment context may matter as much as benchmark performance.
The practical value is discipline. A safety case makes a team write down what would have to be true before deployment is acceptable. It asks what evidence supports those claims. It makes assumptions visible. It clarifies who reviewed the evidence. It defines what changes would invalidate the case after launch. That is a different artifact from a risk register, a policy, or a legal checklist.
Why safety cases matter now for frontier AI deployment
The need for safety cases grows as AI systems become more capable, more connected, and harder to evaluate with one test. A model that only drafts text in a sandbox has a narrower safety problem. A system that can use tools, call APIs, browse files, write code, influence decisions, or coordinate workflows has a broader one. Safety evidence must cover not only the model, but the model inside a real deployment environment.
The International AI Safety Report 2026 emphasizes the evidence dilemma: capabilities and deployment contexts can move faster than robust evidence about risks and mitigations. That does not justify panic or prediction theater. It does mean that deployment decisions need clearer evidence, review, and update triggers than “we ran some tests before launch.”
The source pillar explains the broader framework stack. NIST AI RMF gives risk-management language. ISO/IEC 42001 pushes organizations toward management systems. The EU AI Act creates legal categories. Responsible scaling policies set capability-linked safeguards. A safety case sits inside that stack as a specific argument for one deployment decision.
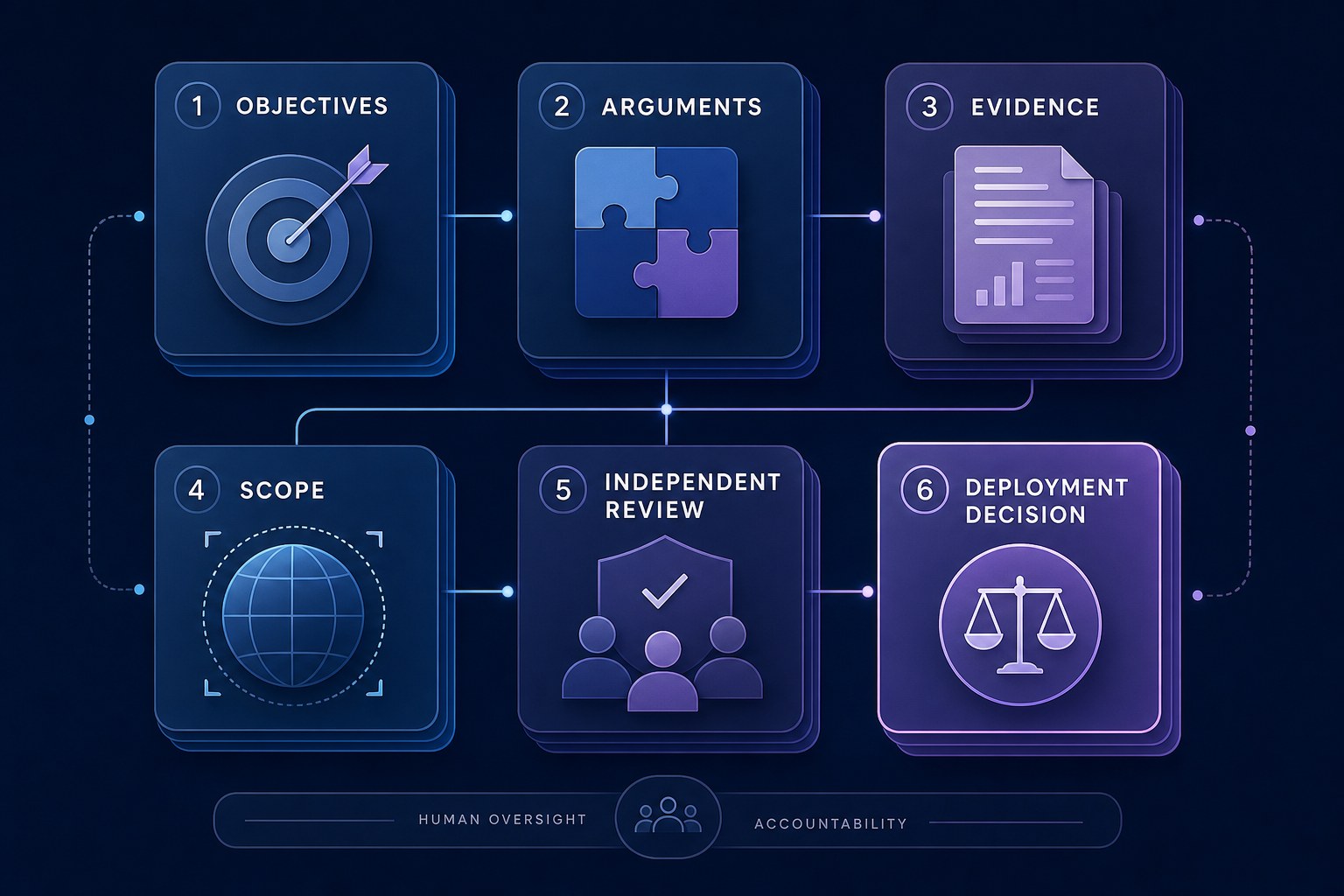
The four components of a useful AI safety case
A usable safety case should be understandable to technical reviewers, governance leaders, and accountable decision-makers. It should not be so vague that every claim is untestable, and not so technical that only one model team can read it. Start with four components.
| Component | Question it answers | What weak versions look like |
|---|---|---|
| Objective | What must be true for the system to be safe enough in this context? | Generic goals like “be responsible” or “avoid harm” with no deployment boundary. |
| Argument | Why do we believe the objective has been met? | A list of controls without explaining how they reduce the specific risk. |
| Evidence | What supports the argument? | One benchmark, one red-team note, or one sign-off treated as enough for all risks. |
| Scope | Where does the safety claim apply, and when does it expire? | No boundary around model version, users, tools, data, geography, risk class, or update trigger. |
These components help prevent the most common governance failure: mistaking activity for justification. A long control checklist may show activity. It does not automatically show that the system is safe enough to deploy. A safety case should connect each control to a claim, each claim to evidence, and each evidence source to a decision.
What evidence should teams collect before deployment?
The AI Security Institute notes that future AI safety cases may combine empirical evidence, conceptual arguments, mathematical arguments where possible, negative evidence such as failed attempts to break a safety method, and sociotechnical evidence about deployment context and organizational controls. For most teams, the immediate task is not to write a perfect frontier-lab safety case. It is to collect enough evidence to make a deployment decision honest.
| Evidence type | Examples | Best use |
|---|---|---|
| Capability evidence | Task evaluations, tool-use tests, autonomy tests, domain-specific performance checks, regression tests. | Shows what the system can and cannot do in the intended context. |
| Failure evidence | Red-team results, jailbreak attempts, prompt-injection tests, hallucination samples, incident simulations. | Shows how the system fails and whether safeguards catch failures. |
| Control evidence | Permission boundaries, human approval logs, sandboxing, rate limits, access reviews, rollback plans. | Shows whether mitigations are real, active, and owned. |
| Context evidence | User groups, affected stakeholders, data sensitivity, workflow dependency, legal or domain constraints. | Shows whether the deployment environment changes the risk. |
| Monitoring evidence | Post-launch metrics, drift checks, appeal paths, override rates, incidents, audit trails. | Shows whether the case remains valid after deployment. |
| Governance evidence | Decision records, reviewer notes, owner assignments, escalation triggers, independent review findings. | Shows who made the decision and how uncertainty was handled. |
This is where safety cases differ from simple “AI safety documentation.” Documentation can describe the system. A safety case must argue why the documented evidence is enough for a decision. If the evidence is weak, say so. If the scope is narrow, say so. If deployment is only safe with tool permissions disabled or human approval required, say so plainly.
A practical safety case workflow for deployment decisions
For a SINGULARITY PATH reader, the right level is not a legal memo and not a toy checklist. The useful workflow is a disciplined sequence that connects safety evidence to deployment gates.
1. Define the deployment boundary
Specify model version, tools, data sources, user groups, allowed actions, excluded actions, and environments. A safety case without scope becomes a universal claim, which is usually false.
2. State the safety objectives
Write concrete objectives such as “the system must not take irreversible workflow actions without human approval” or “medical suggestions must remain informational and escalated to qualified review.”
3. Build the argument tree
For each objective, explain why it is satisfied. Link to capability tests, mitigations, operational controls, and human responsibilities. Make assumptions explicit.
4. Attach evidence and gaps
Connect every claim to evidence. Mark weak evidence, untested assumptions, and open risks. A safety case gains credibility by acknowledging uncertainty instead of hiding it.
5. Review independently
Use reviewers who were not responsible for building the system where risk is high. Independent review does not remove accountability, but it reduces self-confirming governance.
6. Define update triggers
Reopen the case when the model changes, tools expand, user groups change, monitoring flags drift, severe incidents occur, or regulation and internal policy change.
This workflow pairs naturally with the NIST AI RMF. NIST helps teams govern, map, measure, and manage AI risk. The safety case asks whether the resulting evidence is strong enough for a specific go/no-go decision. The previous cluster article on AI risk registers focuses on a living risk inventory; this article focuses on the argument that deployment is acceptable under a defined scope.
Interactive safety case evidence selector
Use this quick selector to identify the evidence area your safety case should strengthen first. It is not legal advice or a substitute for expert review, but it helps expose thin arguments.
Which part of your deployment feels weakest?
Limits and mistakes: what a safety case cannot prove
A safety case is valuable because it improves decision discipline. It is limited because AI systems are uncertain, deployment environments change, and frontier capabilities are difficult to measure completely. A strong safety case should never imply that every failure mode has been eliminated. It should say what has been tested, what remains uncertain, what controls are active, and what conditions would invalidate the case.
Avoid five common mistakes. First, do not write the safety case after the decision has already been made. Second, do not treat one benchmark as a complete evidence base. Third, do not let the model decide by itself which cases deserve human review. Fourth, do not hide negative evidence; failed tests and red-team findings are often the most useful part of the case. Fifth, do not let the safety case expire silently after a model upgrade or tool-permission change.
A deployment-ready AI safety case checklist
- Define the exact system boundary: model, version, tools, data, users, and deployment environment.
- Write safety objectives that are specific enough to test or review.
- Separate the argument from the evidence; do not let controls masquerade as proof.
- Include empirical, operational, and sociotechnical evidence where relevant.
- Record negative evidence, failed tests, unresolved risks, and assumptions.
- Assign owners for every control, monitoring process, and escalation path.
- Use independent review for high-impact, autonomous, or frontier-like deployments.
- Define go, restrict, delay, redesign, and stop criteria before launch pressure appears.
- Set update triggers for model changes, new tool access, incidents, drift, user expansion, or policy changes.
- Link the safety case to a living risk register so evidence and residual risks stay visible after deployment.
If you are building or governing agentic systems, pair this article with Singularity Journey’s related guides on AI agent governance, AI agent evaluation, and human approval for AI agents. For the broader future context, read The Real Path to AGI.
Final takeaway
The best frontier AI safety case is not the longest document. It is the clearest argument for a real deployment decision. It says what must be true, what evidence supports it, where the claim applies, who reviewed it, what remains uncertain, and when the decision must be reopened. That kind of disciplined reasoning is exactly what AI safety frameworks are supposed to make possible.
FAQ: frontier AI safety cases
What is a frontier AI safety case?
A frontier AI safety case is a structured argument, supported by evidence, that a frontier or high-impact AI system is safe enough for a specific deployment context.
How is a safety case different from a risk register?
A risk register tracks risks, owners, mitigations, and review status. A safety case argues why the available evidence and controls are sufficient for a specific deployment decision.
What evidence belongs in an AI safety case?
Useful evidence may include capability evaluations, red-team findings, failure analysis, permission controls, monitoring plans, incident response procedures, stakeholder analysis, and independent review notes.
Who should review a frontier AI safety case?
For higher-risk systems, review should include people outside the build team, such as security, safety, legal, compliance, domain experts, independent auditors, or accountable executives.
Can a safety case prove an AI system is safe?
No. It can make the argument and evidence clearer, but it cannot guarantee that every failure mode has been discovered or that future deployment contexts will remain unchanged.
When should a safety case be reopened?
Reopen it when the model changes, tools or permissions expand, a major incident occurs, monitoring signals drift, the user group changes, or new regulation or internal policy applies.


No comments:
Post a Comment